Optimal string of variations

These days I am working on a ALPR (Automatic License Plate Recognition) System. but the quality of the images we get are .. not exactly the best. The first pass we do, we detect Vehicles and their respected license plates. after that we zoom in on the license plate. Originally we were going to use Google’s Tesseract. but it seems that no matter how we shape the data, Tesseract is just not producing good results. I then decided to develop my own OCR (Optical Character Recognizer) and since we are looking at license plates and not a page from a book, the characters should stick out like a sour thumb. So I decided to use a single shot detector on the character detection part. Which Yolo is well fitted to do. So we have the first pass with Vehicle and License plate, we zoom and then detect the characters on the license plate on the second pass. but when we zoom, the characters are extremely blurry and pixelated due to digitally zooming in on a low quality image. So we used a deep neural network to up sample the license plate. Getting a clearer image.
When we have a clear image and the regions of the image that contains license plate characters, we can then do character classification. This works well .. Notably there are some instances where we read the letter “B” where the actual letter should be “8” .. due to the character shape this is a understandable mistake. With our high frame-rate I noticed we could run multiple passes and with the collected data figure out what the optimal license plate should be.
Another note as well is missing characters, if we detect “ABC” in one pass, but “AC” in another pass, we need to aligned up the characters of the detected passes.
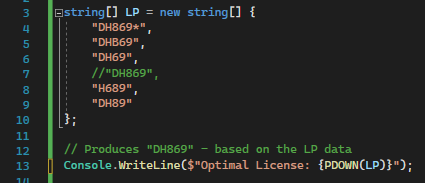
As showed in the image, we have 5 passes. Variations of poor License plate scans. these we can run through a function called PDOWN to produce a guess of the ground truth. in this case the license plate “DH869 is correct”,
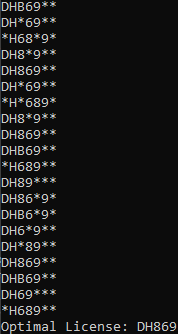
i tried showing that “B” and “8” can get confused. Missing characters and even additional characters. It attempts to align the sequences and with all sequences aligned, we end up with an array of possible suggestions. but we need the average. so we count up the occurrences of a given character in the sequence, cross sequences.
I am using the asterisk as a placeholder for unknown characters, if we detected a character but the classifier couldn’t identify it, or as padding for the PDOWN algorithm. With the given string array, we can see “D” has the highest occurrence in the first index, “H” has the highest occurrence in the second index.
This is the second pass of the PDOWN algorithm, removing the junk and returning with a single result.
I have provided the full source code below, nicely wrapped in a single function. I’ve named it PDOWN for (Pass Double Optimal Wunsch Needleman) as a majority of this is based on the Needleman-Wunsch algorithm .. given that the needleman-wunsch algorithm is used to compare and align two given strings, we needed to iterate this, and create a long list of variations with paddings, and take a second pass and clean it up with a prediction of the given needleman-wunsch outputs.