After Life (Seq2Seq Reanimated)

So a while ago I saw the Black Mirror episode where a person signed up for a service, which had the ability of downloading all mails and chat communications between two people. This enabled the service to create AI that emulated the lost partner after death. Further more, today i saw a TikTok that explained a news article that someone has actually developed a chat AI to simulate a dialog with a lost girlfriend.
I’ve thought about this for a long time, and after seeing that TikTok. I thought to myself. Its actually not that hard to make a quick and dirty version of this. Of course its not gonna be perfect, since I’m making this for a TikTok. But lets get the basics down. LSTM (Long Short Term Memory) cells are perfect to set this up, although the original story of this guy, detail his access to Open-AI tech, we are not so fortunate. So we are going to take a cheaper route. Introducing Seq2Seq (Sequence to Sequence) learning, its a machine learning algorithm developed by google, if i am not mistaken.
A lot of people have used Seq2Seq for chat-bots and has proven itself outstanding when it comes to translations. Most mainstream machine learning that you see takes place in Python, but since that is the most awful language in existence, we are going to go ahead with C# … I found a really nice Seq2Seq Implementation, which I’m gonna borrow heavily from, since time is not on my side at 11pm and we gotta get to work in the morning.
First we login to our Facebook account, I don’t have a dead ex, but i have an ex, and our written dialog goes in to the gigabytes. Which is perfect for training data. (slightly creepy but i need the data) .. Facebook allows you to download your data and even Facebook Messenger chat history, which is exactly what we need. after we get the data, we need to clean it up a bit. This can be a manual process, but since we are speaking of a lot of data, I’ll be creating a small tool which automates this. The result is a JSON file which contains a dialog history between two parties.
We are going to take this JSON and feed it to the Seq2Seq model.. a seq2seq model is quite monotone for this purpose, but still good enough for this demonstration.
You ofc have to take in to account that you need to set the epoc high, i set mine to 300 epoc and out of 1200 dialoged sentences i got an okay, or poor result, depends on how you look at it. its all about the data.
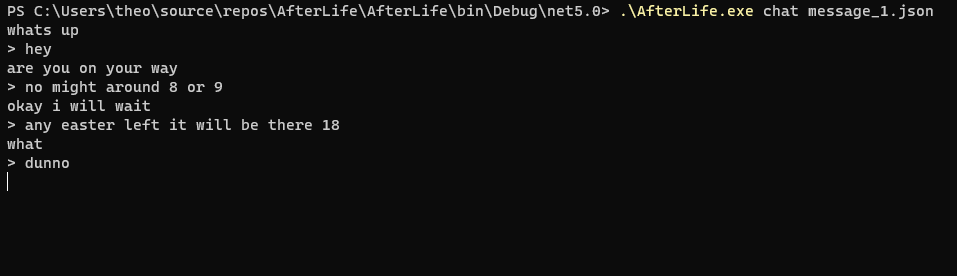
Also, it takes a while to train, with my 300 epocs on an i5 9th Gen, it took about 2 hours give or take. so when i say its all about the data yeah, but its also about the Pentiums (to lazy to do CUDA tonight)
ps. a lot of credit goes to this library: https://github.com/mashmawy/Seq2SeqLearn